






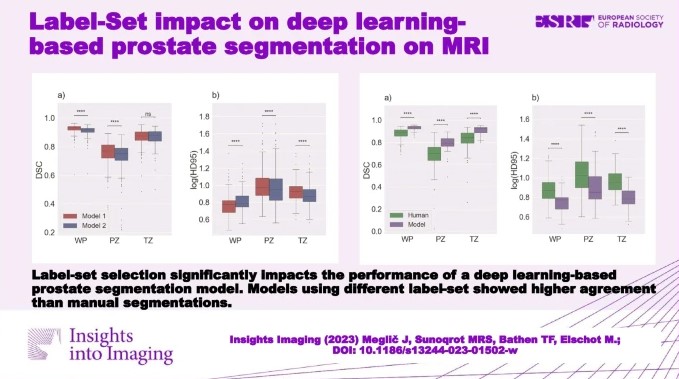
This study delves into a less-explored territory in automatic prostate segmentation: label-set selection. Recognizing the emphasis on dataset selection in segmentation model training, we thought it crucial to investigate the impact of the labels, i.e. the manual segmentations, on model performance. Although label sets are often considered the gold standard, as they are provided by highly trained professionals, disparities emerge across both institutions and individual experts. This was confirmed in our study, where in comparing two label-sets from different institutions on the same dataset, significant differences were noted.
We trained two nnU-Net segmentation models — recognized as state-of-the-art in medical segmentation applications — utilizing the same dataset but with different expert label sets. We found that label-set selection has a measurable impact on the performance of segmentation models, both in the training and in the testing phase.
Having the advantage of two independent expert label-sets for the same data set, we were also able to compare the deep learning-derived and manual segmentations of one set with the second set of manual segmentations. Interestingly, the deep learning models surpassed the performance of the experts who were used to train them. Similarly, we found that the agreement between deep learning models was higher than between their expert trainers. These are indications that the deep learning models truly learned from the images rather than mimicking their training label-sets.
In conclusion, caution is warranted when comparing segmentation models trained with different label sets, even when curated by experts and on the same training dataset. For prostate segmentation, deep learning segmentation models may perform more consistently than radiologists.
Key points
- Label-set selection has a significant impact on the performance of automatic segmentation models.
- Deep learning-based models demonstrated true learning rather than simply mimicking the label-set.
- Automatic segmentation appears to have a greater inter-reader agreement than manual segmentation.
Article: Label-set impact on deep learning-based prostate segmentation on MRI
Authors: Jakob Meglič, Mohammed R. S. Sunoqrot, Tone Frost Bathen & Mattijs Elschot