


In radiomics, deep learning methods are increasingly used because they promise higher predictive performance than models based on generic, hand-crafted features. However, sample sizes in radiomics are often small, and it is known that the performance of deep learning models is often critically dependent on sample size. Therefore, it is unclear whether deep models can outperform generic models.
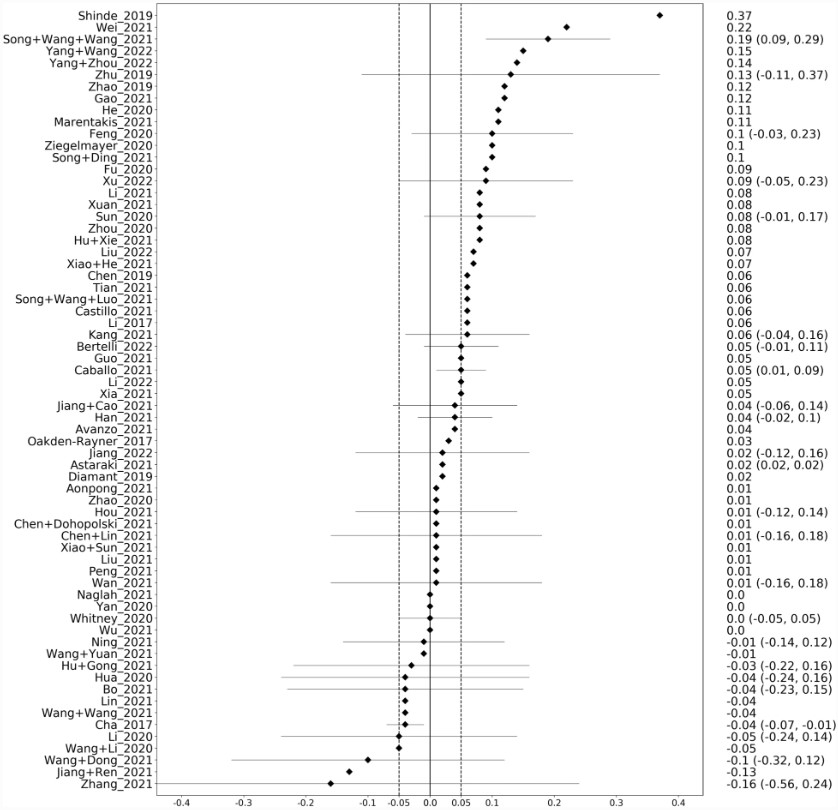
In our systematic review, we identified 69 eligible studies that trained deep and generic models on the same dataset, allowing a direct comparison between the two methods. Our results show that deep models outperformed generic models in the internal validation sets in about three out of four cases, and the median gain in the area under the curve (AUC) was +0.045. In the external cohorts, the median gain was smaller, +0.025, and deep models outperformed generic models in only two out of three cases.
Our results suggest that deep models often outperform generic models. However, there may be a significant bias: Deep models may be prone to more model tuning to ensure that the models perform best, resulting in an unfair comparison. In addition, if deep models do not perform as expected, the results may not be considered worth reporting, indicating publication bias. Therefore, our results should be interpreted with caution.
In conclusion, we recommend that radiomic studies use both generic and deep models to maximize predictive performance.
Key points
- Deep learning (DL) models outperform generic models often but only in 3 out of 4 studies.
- Fused models can improve over the generic and DL models.
- Data leakage, model selection and optimisation, and publication bias could affect the comparison between generic and DL models.
- It is worthwhile to explore both modelling strategies in practice.
Article: Are deep models in radiomics performing better than generic models? A systematic review
Authors: Aydin Demircioğlu